
Edit: This post has been updated! If you’ve read Part 1 already, skip ahead here to the riveting conclusion…
WordPress had humble beginnings in the b2 blogging software, but has grown to be the CMS powering over 43% of the web. Alongside this, the functionality has improved substantially, morphing from just blogs to powering fully-fledged enterprise DXPs like Altis. WordPress now contains a lot of functionality out of the box, but did you know it also includes a miniature Turing-complete programming language?
Deep within the internals of WordPress, you’ll find a parser and interpreter for a tiny C-like language. It’s called “Plural_Forms” but was originally codenamed “Temaki”, and it’s the key to complex translations of plural phrases.
How plurals work
For native speakers of English, you may not have thought too deeply about the rules of plurals. At its core, plurals are a way that words change based on a number that you’re talking about. For the most part, this boils down to just two cases: the singular, and the plural.

In English, the singular noun acts as a kind of base case, and plurals typically have a suffix added; namely, -s. (Many words have different endings – think mouse and mice – mainly to confuse non-native speakers.)
This form of pluralisation is common across many world languages, but it’s not the only way that nouns change based on their numbers.
In some languages, things get much more complex. They may have 3, 4, or in the case of Arabic, 6 different forms. Some languages like Chinese (and emoji!) don’t distinguish at all based on the number.
Translations in WordPress
WordPress strives to be a globally-accessible project, serving users all around the world. To do that, WordPress has a full translation system allowing the user interface to be presented in the most accessible language for users.
This translation system is inspired by (and compatible with) a system called “gettext”, which was originally built for translating software in POSIX systems in the 1980s. gettext provides a way to mark text in the software for translation and to replace that text before it is displayed to the user.
One key insight of gettext was that both of these aims can be achieved by providing a short function just for translation, and then using static analysis to pull all of the text out of the codebase. This provides an easy way to integrate translation into a codebase: just wrap any translatable text in a call to _(). (This differs from many other translation systems, which use string IDs, and hence separate the strings at development time.)
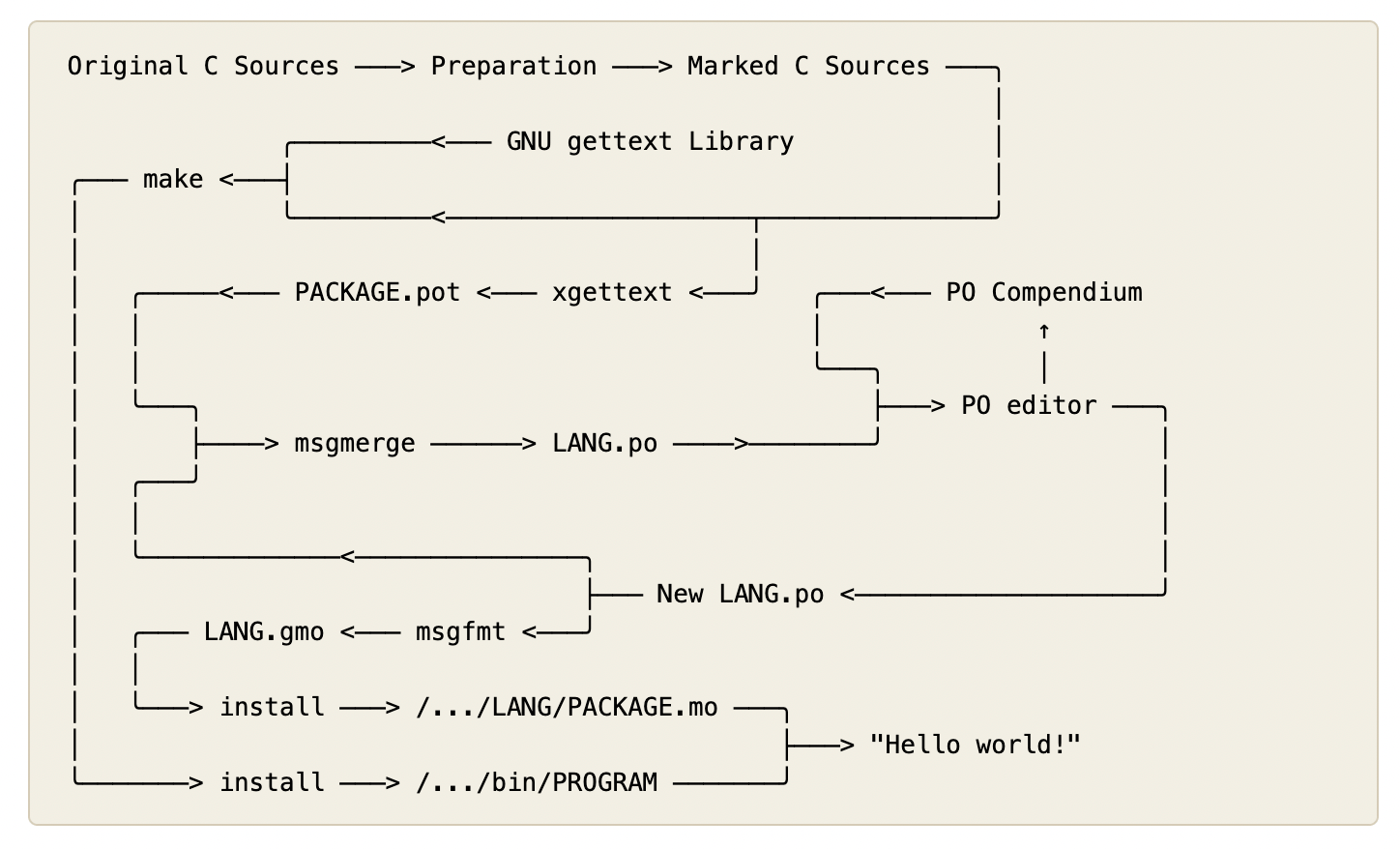
This works great for simple strings like “Welcome to WordPress”, and when used with text interpolation functions like sprintf(), even allows placeholders like “Howdy, %s!”. But it doesn’t have the ability to vary strings based on a number.
One naive solution to this in English is to include both variants, such as “see the example(s)”. This works for the most simple cases, but even in English breaks for the more complex plurals (like cactus/cacti) and often can’t be translated very well.
Another naive solution would be to implement a check to use different strings based on the number. But as noted previously, many languages have a different number of plurals, so this would require much more complex code to select the correct plural.
gettext solves this problem by introducing the ngettext() function, and a concept called plural forms. (This function is often abbreviated to n() or n_(); in WordPress, gettext functions get an extra _ added, since the PHP gettext extension already uses the original names.)
ngettext and PO files
ngettext works by storing multiple translations of one string and differentiating between them using indexes, just like an array.
For example, ngettext( ‘%d block is disabled’, ‘%d blocks are disabled’, $num ) would generate a PO file looking like:
msgstr[0] “%d block is disabled”
msgstr[1] “%d blocks are disabled”(Examples trimmed for brevity.)
This means that in languages that have more or fewer plurals, additional forms can be added. For example, Croatian has 3 plural forms, so the translation here can be:
msgstr[0] “%d blok je onemogućen”
msgstr[1] “%d bloka su onemogućena”
msgstr[2] “%d blokova je onemogućeno”This allows us to have multiple forms of a term based on an input number, but how do we distinguish between them? How do we encode the rules of language?
Plural forms
ngettext has a second part to it: plural forms. This is a way of encoding how to map a number n to a form. gettext originally comes from C, so naturally plural forms are written using C syntax.
For example, in English, if n is 1 then we use the singular form, otherwise we use the plural form. This can be encoded into a plural form as:
n == 1 ? 0 : 1That is, use the 0th form if n is 1 (singular), otherwise use the 1st form (plural).
For a language like Inuktitut, the plural form is:
(n == 1) ? 0 : ((n == 2) ? 1 : 2)In other words, if n is 1, use the 0th form; if n is 2, use the 1st form, and in all other cases, use the 2nd form.
Going back to our Croatian example, the plural form is (deep breath):
(n % 10 == 1 && n % 100 != 11) ? 0 : ((n % 10 >= 2 && n % 10 <= 4 && (n % 100 < 12 || n % 100 > 14)) ? 1 : 2)As you can see, plural forms can get complex quickly, and can involve complex operators like modulo, boolean logic, numeric comparison, and ternaries. These generic maths rules allow gettext and WordPress to handle plurals in any language in a generic way.
How WordPress handles plural forms
In these examples, I’ve been giving the plural forms in the original C syntax, but WordPress is written in PHP, not C. Plus, it doesn’t have a compile phase, and language packs can be downloaded dynamically.
Prior to WordPress 4.8, WordPress handled plural forms by taking the C plural forms, and translating them into PHP. C and PHP’s operators are almost the same, so it’s as simple as adding a $ in front of the n to turn it into the $n variable, then running eval()… right?
Except that PHP differs from C in one important way: ternaries in PHP are left-associative, while in C they’re right-associative. In other words, nested ternaries work differently across the languages. This requires a much more complex process to translate between them efficiently.
It also uses eval(), and eval is evil. It’s not just theoretical bad practice either; this represents an attack vector to WordPress, since anyone who contributes translations could get a back door to your site, and perform Remote Code Execution.
Security controls and moderation have always been in place for the official WordPress.org translations, but this isn’t necessarily the case for translations hosted in other places or translations on more complex sites. Plural forms are usually benign, but for those cases, nothing would stop a malicious actor from adding other arbitrary code into this.
The final straw that broke the camel’s back was that the eval function used for this (create_function()) was deprecated in PHP 7.2, and removed in PHP 8.0. WordPress had to change, and just switching to eval() wouldn’t have fixed any security problems.
Creating Temaki
As part of my role on the WordPress security team, I worked on creating a better way to handle plural forms. I know a thing or two about parsing obscure input, and the micro-language of plural forms seemed ripe for a very simple parser and interpreter. This parser would handle a very restricted subset of C, not allow any non-mathematical operations (or loops), and would remove the need for funky hacks like changing ternaries. (It also doesn’t have the ability to store values, making it non-Turing complete.)
I codenamed this project “Temaki”, which is Japanese for “hand-rolled”, as I wrote the parser from scratch. This project eventually ended up in WordPress as the Plural_Forms class.
Temaki performs two distinct steps: parsing plural forms into a set of operators, and executing these operators.
To parse the plural forms, it works character-by-character through the input string, and uses the shunting-yard algorithm to build a set of operators in Reverse Polish Notation. It builds these into three types of tokens: “var”, indicating the n variable, “value” indicating a static integer, and “op” indicating an operator which can take any number of operands from the stack.

It then later executes these by taking each token one-by-one and performing actions as needed. It pushes either static “value” integers or variable “var” integers to the stack, and then each type of “op” takes as many operands as needed to execute.
All of this parsing is run when the translation is loaded, and the execution is performed as needed. Executions are cached via memoization, and with this, performance matches or exceeds the original eval-based solution.
Try it yourself
The original Temaki repository is now open source and is ISC licensed for any other projects that may want to use the parser for inspiration (or as-is!). Check it out, and read through the code to see how it works; it’s straightforward, although the algorithms can be a little tough to get your head around (Reverse Polish Notation isn’t the most ergonomic way to read algorithms).
Plural_Forms has essentially been untouched since it was originally added to WordPress and has been in production usage across WordPress sites since 2016.
Security by design
Temaki changed how plural forms work to be inherently safe, by switching from code execution which needed to be locked down, to a parser designed to only perform a few, safe actions. This eliminated any possibility of remote code execution.
Likewise, Altis implements security by design throughout many of our systems to eliminate whole classes of security bugs. Our read-xor-execute filesystem with segregated user uploads eliminates remote code execution bugs, while full isolation of every customer environment means that exploits from another customer can never affect you. Plus, our integrated tools for audit logging, web application firewall, and static code scanning provide defense-in-depth against exploits and attacks.
Want to learn more? Discover the full Altis Developer Experience, and chat with our team today.