
As a cloud hosting provider for high-traffic sites, security and availability are among our highest priorities. The biggest threat to both comes from malicious traffic, usually DDoS attacks. These attacks are overwhelming floods of requests from different devices all over the world, with the aim of denying users access to a particular site by overwhelming the site with requests. Unfortunately, the frequency of these attacks is only increasing.
47 million malicious requests per minute ought to bring down a website, but that’s exactly what a client of ours withstood. Here’s how Altis Cloud successfully defended a website of 90 million monthly requests against a large-scale DDoS attack with zero downtime.
Availability starts with infrastructure
In 2021, an Altis Cloud client was entering a period of particular importance for publishing in its industry: continually delivering content to its audience was therefore paramount. However, the content being served was only as good as its availability; if valuable content is unavailable, then it has no value. This raises the question: how do you ensure availability for such a high-value site, even in the face of malicious attacks?
(Queue the drum roll)… Infrastructure!
As an AWS Partner, we host Altis on AWS’s Cloud infrastructure. For us, availability starts at the infrastructure layer, and this is evident in the Altis Platform design as shown below:
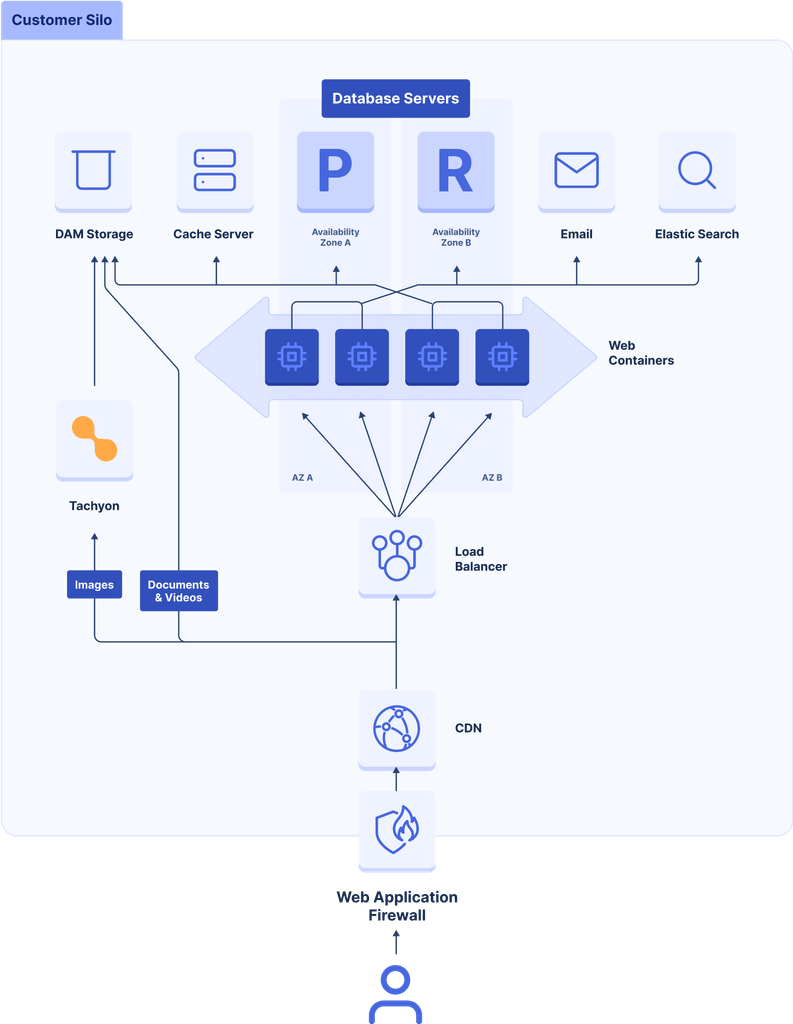
The Altis Cloud infrastructure is configured and optimized for high-availability under adverse circumstances.
We host client sites on a loosely-coupled microservice infrastructure which ensures availability through the following features:
- High availability: To provide high availability, we configure the underlying servers (application, database, and cache) to be spread across multiple availability zones in order to accommodate the failure of a single availability zone within an AWS region.
- Elasticity and scalability: To ensure a site can scale to meet changing traffic demands, we run the backend web servers in a stateless docker-containerized environment. This enables easy scale-out via autoscaling in response to high traffic by adding new containers and scale-in when there is lower traffic. We configure the database servers to automatically scale based on load, adding and removing additional reader instances to the existing write instance as needed (known as “horizontally scaling”). Reader instances are automatically distributed across availability zones and are promoted to writers for instant disaster recovery when required. We also use LudicrousDB, a special WordPress database drop-in, that allows us to communicate with multiple database servers from within WordPress, splitting reads and writes, load balancing, sharding, and a lot more.
- Persistent object caching: We use a highly available Redis cluster to service frequent DB requests. The Redis cluster acts as a key-value cache store, offloading expensive queries from the database using the WordPress Object Cache interface.
- Page caching: We use page caching to improve page delivery time to users via our forked version of batcache.
- Static file caching: We use static file caching to increase the availability of site assets by caching them at Global CDN edge locations closest to the users.
- Enterprise-grade security: We provide enterprise-grade security via Web Application Firewalls and advanced DDoS protection technologies, which perform traffic filtering to ensure only legitimate traffic is allowed into the client environment.
A look at different types of DDoS attacks
The major threat to a website’s availability comes from malicious traffic, usually in the form of DDoS attacks. This was what we faced just two weeks following the launch of our client’s site. But before we dive into this threat, let’s look at what DDoS attacks are.
DDoS attacks refer to a flood of requests from different devices all over the world, with the aim of denying users access to a particular site by overwhelming the site with requests. It has two broad categories:
1. Infrastructure layer attacks
This type of attack is performed at the network and transport layer of the infrastructure, with Server IP addresses typically being the target. Anyone with a credit card can easily launch infrastructure layer attacks.

2. Application layer attacks
This type of attack predominantly targets ports 80 and 443 on websites. They are more complex and harder to launch. A common type of application layer attack is the HTTP flooding attack, which was the type of attack that posed a threat to the availability of the client site.
More specifically, in HTTP flooding the attacker uses seemingly legitimate but malicious HTTP GET and POST requests to overwhelm a targeted site with traffic. This causes the site to become unresponsive because it allocates all its resources in an effort to respond to the malicious requests, and therefore has no resources left to respond to additional legitimate requests from real users.
But why would the client be attacked?
DDoS attacks are usually well planned and structured to accomplish the goal of making a site unavailable to real-world users. It all starts with a motive. DDoS attacks can result from motivations such as cyber-vandalism, extortion, business competition, etc., but in our client’s case, Hacktivism motivated the attacks on the site.
Hacktivism refers to Cyber attacks launched by individuals or groups with social or political motivations.
Taking a closer look at the DDoS attacks
The first of the attacks started on Dec 15th, 2021, when the client site received a massive HTTP flood. The graph below shows the number of blocked requests every minute:
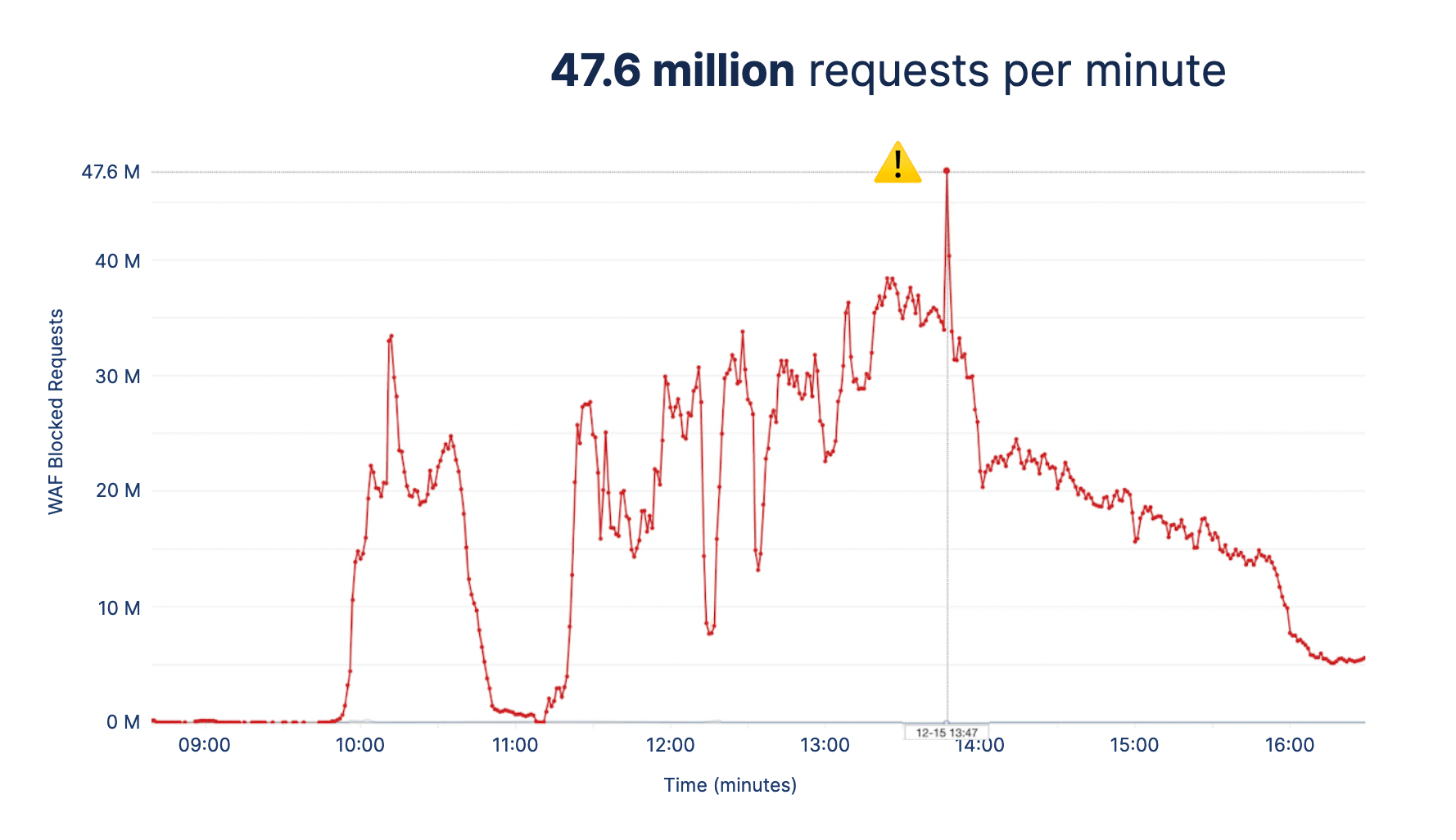
The attack lasted for over 6 hours and peaked at 47.6 million requests per minute. At that point, the environment was running 25 t3.medium server instances and 101 container tasks to absorb the traffic influx.

To put this into context, Kaspersky’s 2022 Q1 report noted that less than 6% of all their DDoS attacks lasted for 5 hours or more, and the average DDoS attack duration for Q1 of 2022 was just under two hours. This shows that the attackers meant “business”.
The peaks and troughs show how the attackers employed a “hit and run” method by sending a high volume of traffic and then disappearing, only to return a few minutes later with a higher volume of traffic to keep the engineers guessing whether the attack was over and to catch us off-guard. We successfully mitigated each hit with a combination of security strategies (which are mentioned further down). We have seen even larger attacks since this event and have continually succeeded in mitigating them.
Maintaining continued uptime despite DDoS attacks
During DDoS attacks, you would expect panic stations and all hell breaking loose from the client due to lack of access to the site under attack, but the fact that the client was posting updates on their site about the DDoS attacks while the same site was being DDoSed is a testament to our efforts in ensuring availability at all times.
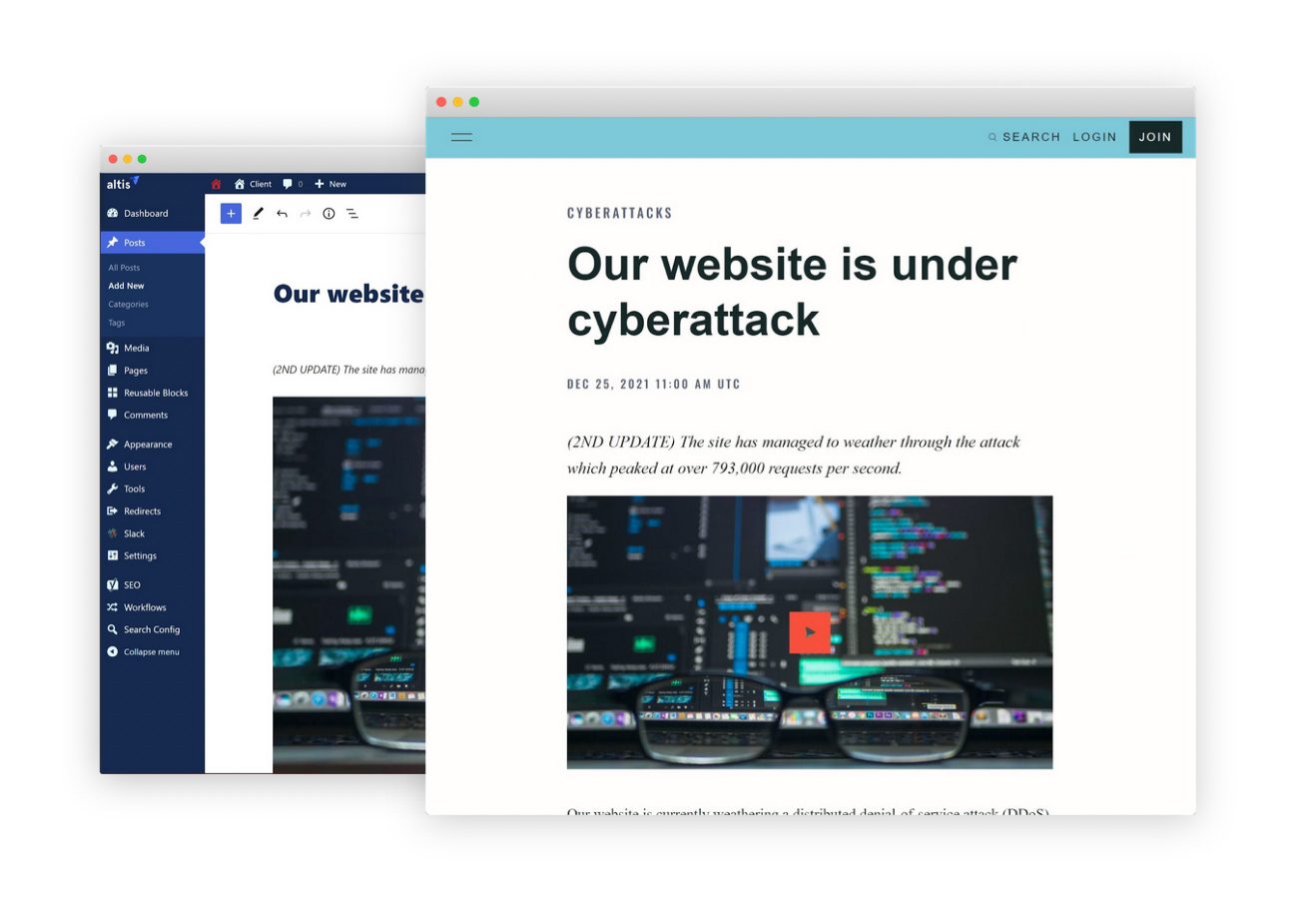
The client was able to actively inform visitors of the attack from the website while it was being attacked.
The expected and unexpected
In responding to the attacks, it was important for us to have our mitigation strategies in place in advance because trying to plan a mitigation strategy while being under an attack is obviously quite difficult. We had to be prepared to respond to ‘the expected’ and ‘the unexpected’.
From the onset of the project, we knew that the client would be a target of DDOS attacks due to their reputation for providing high-value news. This was ‘the expected’.
One of the mitigation strategies we used to combat the expected was autoscaling to absorb the huge influx of traffic. This gave us time to think and adapt to the different patterns of attacks. Autoscaling also made it difficult for the attackers to sustain the attacks for long periods as they had to work harder to scale their attacks due to our infrastructure scaling automatically. It’s important to note that this strategy does have its cost implications since more servers are spun up while scaling out, so implement it wisely :).
In addition to autoscaling, we implemented security tools such as AWS’s Shield Advanced service, which provided us near real-time visibility into the attacks, integration with AWS WAF, and a DDoS response team for additional support. We were able to perform an on-the-fly analysis of the attack from the real-time data provided and make more accurate decisions on extra mitigation strategies to implement to eliminate the threat.

During an attack, it is common for attackers to change methods and try to attack in different ways. This constituted ‘the unexpected’. We had to be prepared to respond to this.
Because the attackers kept changing the attack patterns, we had to leverage Cloud Engineer experience within the Altis team in assessing the attack patterns and creating custom rules on the fly to mitigate the varying attack patterns.
The attackers targeted the home page and specific recent posts on the sites by making GET requests using randomly generated query strings such as “/?B268815232114s2136598741371K” to bypass the cache in an attempt to force the traffic to be sent directly to the web containers in order to overwhelm and ultimately kill the web containers. POST requests to “/wp-admin/”, “wp-login.php” and xmlrpc.php” were also used to achieve the same goal, as well as requests from unknown user-agents such as “null”. We quickly mitigated each of these by creating regex WAF rules to block such malicious requests.
One of the key success factors for us was the fact that we constantly learned from each attack and used the lessons to improve our mitigation strategies. The result of this is a set of battle-tested WAF rules which provides auto-mitigation using IP rate-limiting, HTTP header & Query string filtering, and blocking of IPs with bad reputations.
How we strengthened Altis Cloud following the attack
Since the first attack last year, we have grown from performing manual interventions to using automated mitigations in response to DDoS attacks. This saves us the cost of engineering time spent on dealing with the attacks manually.
Although our client still experiences large DDoS attacks, the effects of these attacks are usually not visible because they are dealt with automatically.
The continual improvements to ensure our clients experience high availability despite DDoS attacks ultimately build client confidence. At Altis DXP, we care about client outcomes, not just hosting.
For further reading on our infrastructure and security features, check out the below following in the Altis docs:
- https://docs.altis-dxp.com/cloud/architecture/
- https://docs.altis-dxp.com/cloud/firewall/
- https://docs.altis-dxp.com/security/
- https://docs.altis-dxp.com/cloud/cdn/
Or feel free to book a demo of the platform. We’d be happy to show you around!