
Altis runs WordPress at scale for high-traffic and enterprise clients around the world. Our customers run lots of scheduled and one-off tasks, and we’ve fixed wp-cron to work at scale for them, executing hundreds of thousands of jobs a day. If you want scalable high-performance jobs, check out the Altis Cloud platform.
WordPress is the world’s most popular content management system, powering over 43% of all websites. The main job WordPress has is to show your website: when a user requests your website, WordPress generates a response as an HTML page (we call this the request-response cycle). But in order for WordPress sites to function, there’s a lot of background work that needs to happen too, which doesn’t fit into this pattern.
WordPress includes built-in functionality for running this background work, using the Unix cron model, imaginatively called wp-cron. This allows executing one-off tasks at a specific time (such as for scheduled posts), as well as running repeated scheduled tasks (like cleaning up old revisions).
wp-cron is a clever system built into WordPress, but unfortunately it’s a system that can fall down for high-scale WordPress sites. Altis deals with sites with hundreds of millions of page views and large teams; making sure these tasks succeed is critical for their editorial workflows and timely publishing.
To solve these problems, we created Cavalcade, our wp-cron solution. We’ve written previously about Cavalcade, but we figured it was time for an update as well as a deep dive into the general wp-cron system.
wp-cron’s design
wp-cron was first added to WordPress 17 years ago as a basic way to handle these background tasks, working within the constraints of WordPress at the time. The wp-cron system is designed around two fundamental types of tasks: one-off tasks, and repeating tasks.
Both types of tasks have three properties: a time to run at, an action to run, and arguments to pass to the action callback.
Repeating tasks are used extensively throughout WordPress for checks and maintenance operations.
Repeating tasks also have a named schedule associated with them, like hourly, daily, or custom schedules. Schedules have to be registered in code with an interval (in seconds), as well as a display name. (Interestingly, the display name is never actually used in WordPress core!)
A typical one-off task is publishing scheduled posts. When you schedule a post to publish at a certain date and time, WordPress schedules a one-off task to publish the post at the specified time. WordPress uses this same system for various cleanup tasks which need to run some time after the main task, and it’s used widely across the plugin ecosystem.
Repeating tasks are used extensively throughout WordPress for checks and maintenance operations. For example, WordPress uses repeating tasks for checking for plugin and theme updates twice a day, as well as emptying the trash every day.
How wp-cron runs
Unlike our typical request and response pattern for serving up the website, we somehow need to fire off our events at the specific time they’re meant to run.
If you control the server, the typical way to solve this is to set up a daemon, which is a background process that always runs and can fire off at the exact moment. But WordPress is designed to run on any server with PHP, and with the traditional shared hosting environment that WordPress was designed for, you can’t install a daemon.
So how do we bridge this gap?
wp-cron’s clever solution to this is to reuse the request-response cycle. When someone loads your site, WordPress checks when the last wp-cron ran, and “spawns” wp-cron if it’s overdue. But rather than just running your tasks, which could slow down your site, WordPress sends itself an HTTP request (called a “loopback”). This takes advantage of PHP’s ability to send requests without waiting for a response, keeping your page loads snappy.
This allows wp-cron to effectively run background tasks, even without control over the server.
Limitations of wp-cron
Because wp-cron only spawns when someone loads your site, you need to have traffic on your site. This can be an issue for low-traffic sites, and can lead to scheduled posts being published well after their due date.
Paradoxically, this can also happen for high-traffic sites! High-traffic sites often use heavy amounts of caching, which can mean that a CDN or reverse proxy cache ends up serving traffic, and WordPress never gets run at all. In most cases, high-traffic sites won’t hit 100% cache hit rates, but this can still lead to delays and imprecision in scheduled events.
To get around this, the official suggestion is to use your system cron to send the loopback requests and tell WordPress to disable its own spawning. (This is controlled by the DISABLE_WP_CRON constant, which, despite the name, only disables the spawner and not the whole system.)
This works in many cases, but as with many things in WordPress, things break a bit when you run multisite. wp-cron is site-specific, and so has to be spawned for each site individually. If you only have a handful of sites this can be OK, but managing your crontab can become annoying, and the system doesn’t scale to hundreds or thousands of sites.
A better wp-cron
Since wp-cron was designed in the early days of WordPress, a lot has changed in the web hosting world. Shared hosting is much less popular, with hosting plans generally moving in two distinct directions: managed hosting and VPSes (virtual private servers). Managed hosts run hosting highly specific to WordPress, while VPSes allow developers full control over their servers (with grunt work typically handled by server provisioning).
We created Cavalcade, a replacement for the existing wp-cron system, specifically to address the limitations of the built-in solution.
In both of these scenarios, it’s possible to have a WordPress-specific solution to the scheduled tasks problem which doesn’t have the constraints of wp-cron: developers can install it on VPSes, and because managed hosts are set up specifically for WordPress, they can run it for their customers.
We created Cavalcade, a replacement for the existing wp-cron system, specifically to address the limitations of the built-in solution. The primary motivation behind Cavalcade was to ensure scheduled events would run on time for a self-sign-up multisite with thousands of sites, with no manual management of a crontab.
Since we created Cavalcade, it’s become a core part of the Altis offering and is widely used for WordPress at scale, even running on WordPress.org itself.
How Cavalcade works
Cavalcade consists of two parts: a WordPress plugin (“Cavalcade plugin”) and a system daemon (“Cavalcade-Runner”).
Unlike wp-cron, Cavalcade Runner operates as a system daemon, continually watching for due events. As we can install any software we like on servers we control, we don’t have to be shackled to the request-response lifecycle. Running as a daemon also means we can fire off events with whatever precision we’d like, allowing us to run at the exact second we want.
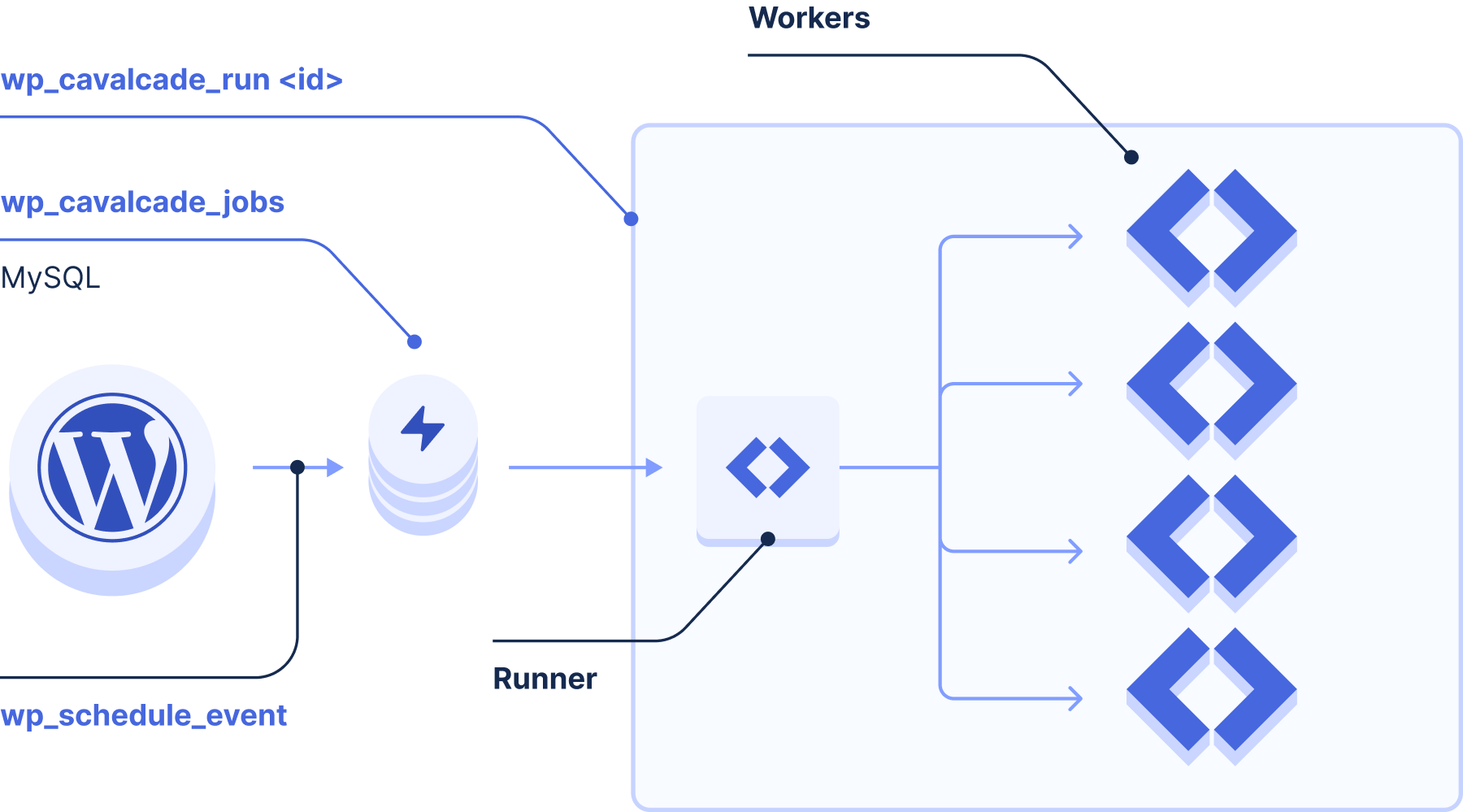
Inside WordPress, the Cavalcade plugin hijacks the wp-cron APIs, meaning that developers don’t need to make any changes to their code, and plugins work automatically. Cavalcade silently replaces the option calls with calls to a specialised database table just for events. This table stores the site ID, action to run, arguments, when to run, status (waiting, running, completed, or failed), and (for scheduled events) how often to run. (We call both one-off events and scheduled tasks “jobs”.)
How does Cavalcade Runner know when jobs are due? It uses the simplest system that could possibly work: every second, it runs a database query against the custom table to find any events that are due (literally WHERE nextrun >= NOW()).
This might seem heretical to performance-conscious developers: “avoid database calls” is basically a mantra! But because we’re using a custom table, we can design our table specifically for this case, with efficient indexes. Plus, once per second is only 86,400 queries a day; a number much, much smaller than the baseload querying our typical sites generate.
In my opinion, custom database tables are underappreciated in WordPress. While custom post types have some great ergonomics, their performance isn’t great at scale.
For efficiency on multi-core systems and to avoid head-of-line blocking, Cavalcade Runner will run up to 4 jobs in parallel, ensuring that jobs don’t need to wait for others to finish while maximising CPU usage.
Internally, when Cavalcade Runner runs a job, it runs a wp-cli command registered in the Cavalcade plugin. This means we get a nice clean WordPress state for each action we fire off, and can use wp-cli’s --url parameter for instant multisite support. It also means the long-running Cavalcade Runner process doesn’t need to load WordPress itself. (Cavalcade Runner is written in PHP for a few other reasons, but in theory, you could write a daemon in any language since they’re decoupled!)
Scaling Cavalcade for massive sites
This design is great for single servers and has served us well on our original legacy platforms. But you know what’s better than one server? That’s right; an autoscaling cluster of servers.
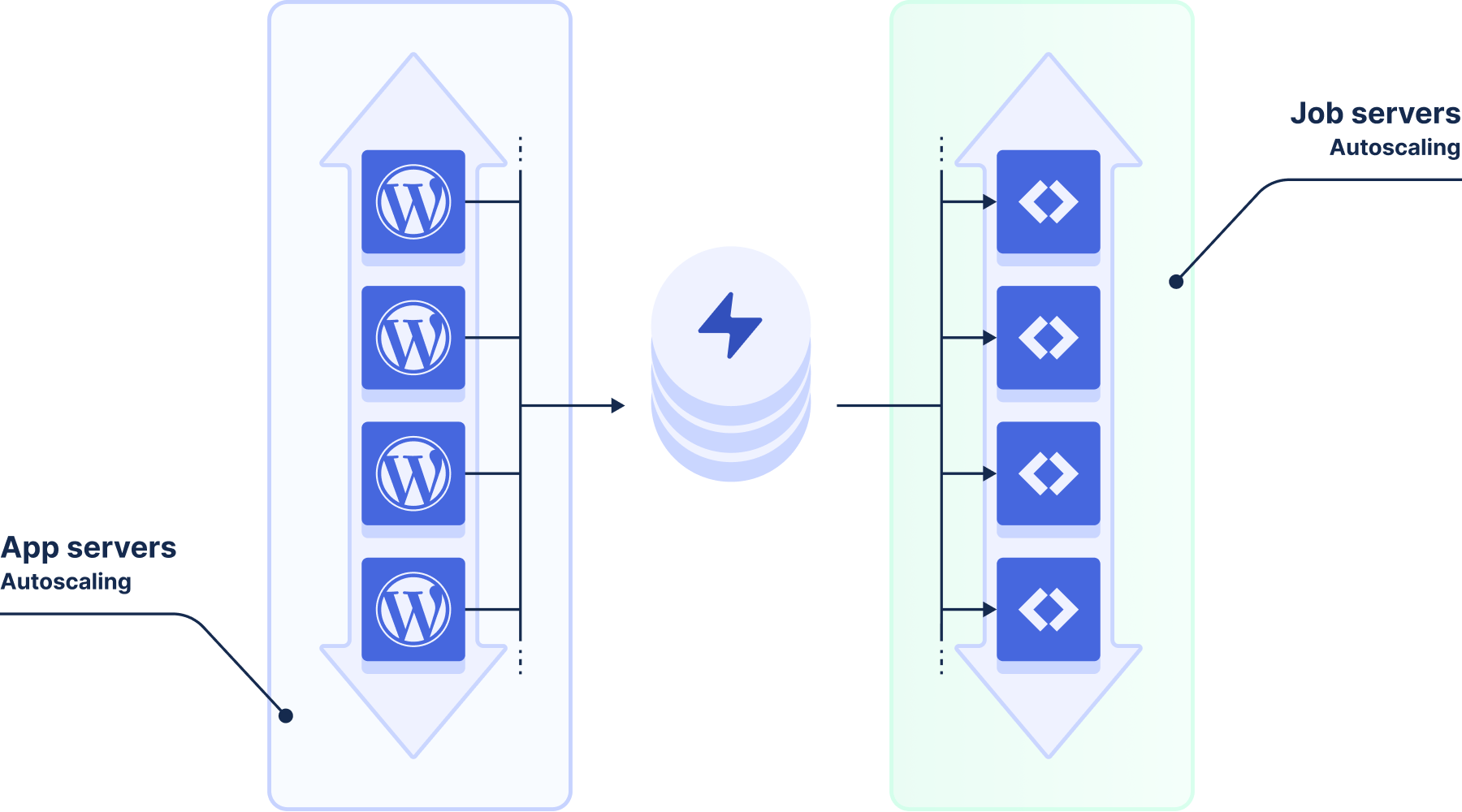
Since Cavalcade jobs are stored in our database, we can horizontally scale Cavalcade by running more instances of Cavalcade Runner and pointing them to the same database. These Runners automatically coordinate using the database table we already have, with a trick.
To make sure that only one Runner is running a job, the Runner updates the database to change the status of the job from waiting to running, but only if the job was still waiting (UPDATE … SET status = “running” WHERE status = “WAITING” and id = :id). Thanks to MySQL’s consistency guarantee, only one runner can perform this update; we simply check to see if the number of affected rows is 1, and if so, we have the lock.
There are other (and likely better!) ways to coordinate runners, including more sophisticated locking, but Cavalcade is based around doing simple things that work at scale.
So that’s horizontal scaling, but how about autoscaling? Because everything in Cavalcade is built around running jobs that are due, we know that to process 4000 jobs, we’ll need 1000 runners. We can use the same database query as the Runner itself in any autoscaling logic. Even better, we can know ahead of time how many Runners we’ll need by peeking slightly ahead into the future, checking how many jobs will need to run 10 seconds from now, and preparing our Runners ahead of time.
You can use any threshold for peeking into the future that you’d like, but we recommend a balance between how long new Runners take to spawn, and how “dynamic” your queue is. (That is, how likely is that number to change, such as with added or removed jobs.)
If you want to optimize for cost instead, you can also measure overdue jobs and use it as a lagging indicator for scaling, at the cost of occasionally running jobs late. This will avoid overshooting and scaling up too much.
Surprise, a queue!
One of the really fun results of having an autoscaling system built on the number of pending jobs is that you can use Cavalcade to process a queue. By scheduling many single events due immediately (or some offset to help your autoscaling prepare), you can process a huge number of queued events very quickly, with your main bottleneck becoming database writes instead (since [WordPress isn’t thread-safe]()).
This is a super powerful tool for processing large amounts of data in parallel (“fan out”), or performing work asynchronously (“off the main thread”). This is important for reducing page load times, especially for important but slow tasks we need to do as part of an editorial workflow.
For example, internally we run a network of P2 blogs we use for communication. When someone publishes a new post or comments, we send an email notification to everyone who’s subscribed. To do this, we schedule a job when the user hits publish. This job works out the recipients, and then schedules another job for each recipient to actually send the email. Cavalcade automatically responds to scale-out our Runners and process the queue of jobs immediately.
Cavalcade effectively operates as an at-most-once queue system: if your job fails for some reason, Cavalcade doesn’t restart it automatically. Cavalcade also offers no guarantees about your queue being processed in order: in fact, in most cases with autoscaling, it explicitly won’t be. (This is in contrast to wp-cron’s behaviour, which is sequential, but can lead to jobs backing up.)
Quirks and gotchas
WordPress runs wp-cron using an at-most-once system, and Cavalcade replicates this behaviour. Each time wp-cron runs, it loops through the jobs that are due and deletes the job entry before it runs. This means if the job fails, it’ll silently disappear and whatever you scheduled to run won’t run again.
Cavalcade works the same, but explicitly marks the job as failed for visibility, as well as recording a log of the run. This behaviour can be confusing if you’re not used to it, and a common request we get for Cavalcade is to implement a retry system to make this behaviour at-least-once instead. We haven’t implemented this system (yet!), but it’s possible to layer this behaviour on top of Cavalcade’s built-in process if desired.
Since wp-cron runs through an HTTP request, it’s subject to server limits. WordPress uses functions like `fastcgi_finish_request()` to avoid using up too many resources, but depending on your PHP configuration, hard limits on PHP runtime may still apply (such as a 5-minute maximum). Cavalcade permits much longer running tasks, but limits are typically still applied to avoid runaway or stuck jobs (on Altis, we limit job execution time to 60 minutes).
Unlike wp-cron, Cavalcade does not delete recurring tasks and schedule the next one. Instead, it marks the job as “running”, and when complete, then schedules it for the next time. In rare cases where the runner is killed by the system and isn’t able to update this status, jobs can “stall” and become stuck in this running status. On Altis, we use alerting systems to find these (rare) failures and correct them. We’re looking at ways to solve this automatically, but fixing this problem is complex in a distributed system without a central watchdog.
When the next recurring job is scheduled, wp-cron adds the schedule to the current time, while Cavalcade instead adds the schedule to the originally scheduled time. This ensures Cavalcade jobs scheduled to run at (e.g.) the start of the hour always run at the start of the hour, whereas wp-cron jobs can drift over time if they run longer than the recurrence schedule. However, in cases where Cavalcade is completely stopped for some amount of time, such as on local development environments, when the system restarts it can run the same job repeatedly as it “catches up”. This can be desired in production environments where it ensures that momentary downtime has little ongoing impact but can cause excessive, unnecessary CPU usage for development environments.
Using Cavalcade
Cavalcade is fully open source, and is compatible with any WordPress plugins using the standard wp-cron functions. Running Cavalcade will require system access to set up the Cavalcade-Runner daemon, but can be installed as a regular user without needing root. Full instructions on usage and installation are available in the Cavalcade repository on GitHub.
Altis Cloud Platform provides Cavalcade as a standard component of our hosting infrastructure, including autoscaling runners to quickly get through your job queue. We run hundreds of thousands of jobs per day across our 7 global regions in America, Europe, and Asia-Pacific (as of writing, we did 330,000 jobs over the past 24 hours!).
If you’re interested in seeing what Altis can do for you, get in touch or book a demo directly.