
One of the secrets of scaling up systems is that as they grow, they can often end up with reduced performance, becoming slower than low-traffic sites.
If you’ve never worked behind the scenes on high-scale architectures before, this might be surprising! After all, high-scale sites typically have large development teams with significant budgets; how can those sites be slower than a site made by one developer?
This is the inherent performance/scaling trade-off: in order to serve more traffic (scale), you may need to make choices which make individual experiences worse (performance).
These factors are intrinsically interlinked, but can be difficult to pick apart. Let’s dive in to the details, and see how Altis helps overcome this trade-off with solutions like Afterburner.
Performance: The speed of excellence
Performance isn’t just about speed; it’s about the quality of service for an individual user. Think of it as the velocity of water flowing through a pipe – the faster it travels, the quicker your site loads for that one user. On the web, we measure this with web vitals, including time to load (TTL), time to first byte (TTFB), and newer Core Web Vitals scores.
We consider performance at the individual level to give us an idea of a single person’s experience. We also look at this data aggregated across all users, often considering the median (p50) and 90th/95th percentile (p90/p95).
Ensuring a speedy single-user experience is not just a luxury; it’s a necessity in today’s competitive market. But here’s the twist: chasing performance alone might make your site a speedster for one but a snail for many. That’s where scaling comes into play.
Scaling: The volume of victory
Scaling is like widening that pipe to handle a large volume of water – or in our case, a massive number of users. It’s all about the requests per second (rps) or per minute (rpm).
Scaling means that as your site grows in popularity (and we hope it will!), it won’t buckle under the pressure.
If your pipe isn’t large enough to handle the flow, you’ll start seeing the pipe back up – if you’ve ever seen an overflowing drain during a storm, this is the cause!
Many wonder why well-funded companies might have slow sites. Often, it’s because they need scale rather than performance. Low traffic sites can be incredibly fast, but scaling brings inherent challenges; it may even slow things down!
Why small is fast, and why it doesn’t scale
So far, this sounds easy to solve: increase the size of the pipe! The difficulty arises when we work out how we can do this with the tools we have available to us.
For simple sites at small scale, we can run our entire site from a single server; for WordPress, this means we run Apache/nginx, PHP, and MySQL all on one box. Since they’re all right next to each other, there’s no communications overhead, so our responses can be super speedy.
As we start getting more traffic, we’ll max out our server’s capacity. The old-school solution to this problem is to increase the size of the server; for example, adding more memory or assigning additional CPUs cores to our site. This is called “vertical scaling”.
Vertical scaling can be a slow process, involving complex server migrations or physical hardware upgrades – our customers have told us other hosts sometimes took weeks to upgrade their servers, leading to lost revenue. It also has severe limitations, since there’s a finite limit of how many CPU cores you can have, and when you’re not using the capacity it’s effectively wasted. Aside from being expensive, low CPU utilization can also be power-inefficient and lead to higher carbon emissions.
Cloud-native: Scaling out horizontally
The more modern, cloud-native model of scaling is “horizontal scaling”. In this model, rather than having one large server, we have many smaller servers pooled together. When we receive more traffic, we add more servers to this pool to add additional capacity – like adding more pipes to our network. This can also act as a high-availability architecture, giving us redundancy against failures.
Scaling horizontally means we need to architect our whole system for multiple servers, including routing inbound traffic equally across our servers, and ensuring any data we store can be shared. In particular, we need to share the database across all of our servers so that they’re displaying all of our data consistently.
Moving our database server out creates additional overhead with network latency, throughput, and any transport encryption we might need to keep data safe. This overhead is inherent – the nature of separating our servers creates it. This is where we start to see the performance-scale dichotomy appear: in order to support higher scale, we have to change our architecture to something slower.
But, doesn’t cache rule everything around me?
Caching, the method of storing and reusing previously fetched or computed data, is often seen as a golden solution to performance challenges. You might be wondering, “Why not just cache everything?” If only it were that straightforward!
The WordPress way to cache data is object caching, which moves many database queries out to a key-value store. This improves performance by moving from relatively-slow queries (which may need to read many objects from a table) to fast lookups, using database software specifically designed for this purpose (originally Memcache, with Redis being the more popular choice now, including on Altis).
This will improve performance across the board, however it doesn’t solve the inherent problems with separating our servers. We still need a central cache server, to avoid the ‘split-brain’ problem, where different servers hold conflicting versions of the cached data. (Plus, object caching won’t bring us back up to baseline performance, because object caching is table stakes on any serious hosting.)
In fact, it can make the problem worse! As we move from one large, slower database query to many small cache lookups, the network overhead can add up; a 0.5ms overhead on a 150ms query is insignificant, but if you make 100 1ms cache lookups, each of those incurs a 50% penalty!
Techniques like pipelining and connection reuse can help to mitigate these issues by minimizing the worst connection overheads. We can also ensure that our cache servers are located as physically close as possible to our application servers. But, at the end of the day, we still end up with a high-scale site that is inherently slower than a small-scale site.
This is the performance-scaling trade-off, and it’s something we have to live with every day… or do we?
Inspiration inside
Computation separate to data. A caching layer. Scaling computation in parallel. Overhead due to transmission. These are all the factors of our high-scale performance problem… and they’re the same problems that CPU architectures face.
When CPUs began to increase in power (vertical scaling), they needed to introduce a caching layer to ensure data was always available when needed. With multi-core CPUs, the idea of private vs shared caching arose, where each core could have its own (very close, very fast) caching layer, which coordinated with the (further away, but still fast) shared cache. In modern CPUs, each core has its own “L2” cache, which builds on top of a shared “L3” cache (the “L1” cache is private, and is like our in-memory, request-lifetime cache in WordPress).
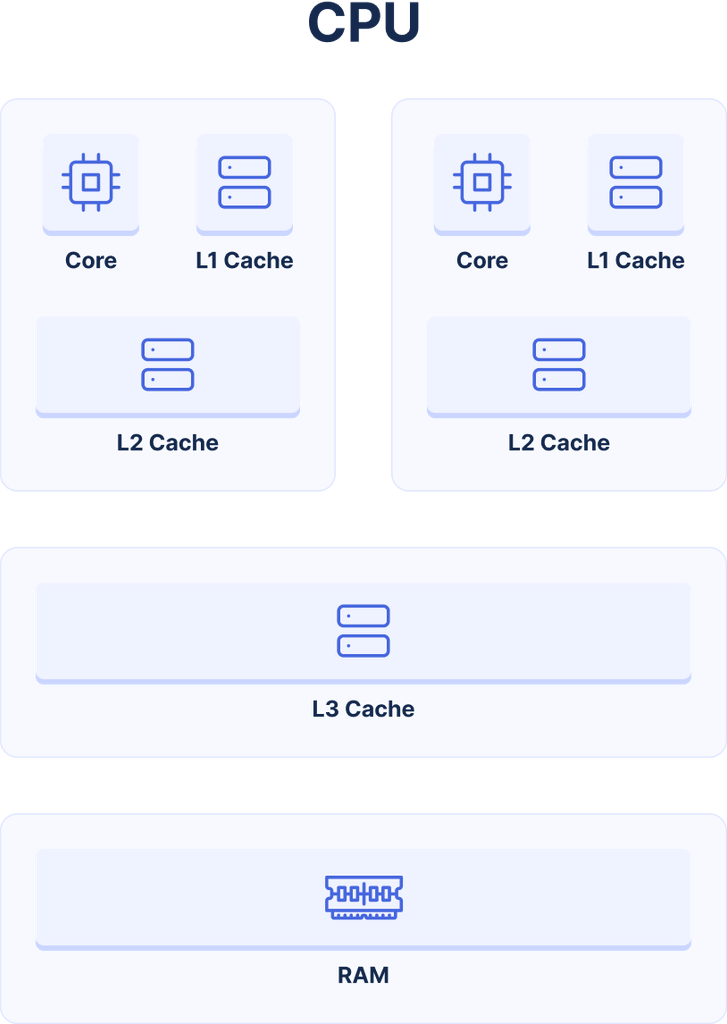
We can take inspiration from this, and we’re not the first to do so – our friends at Pantheon were one of the first to realize this, and created LCache to implement this for both WordPress and Drupal.
Afterburner implements this layered cache system, with our Redis server acting as the “primary”, and each PHP instance containing its own “replica” cache (Afterburner Cache).
However, moving to a multi-layer cache has its own challenges, including introducing the split-brain problem. It’s vitally important to keep your caches in sync with each other, or your site may operate differently depending on where it is – this may be one of the reasons Pantheon later withdrew their LCache solution.
Flipping the script with push-based invalidation
There are various techniques to handle this split-brain problem.
One solution would be to poll repeatedly to see if any values have been updated. This would operate as an eventual-consistency system, allowing stale cache reads temporarily. WordPress is not fundamentally designed for this, nor are plugins in the ecosystem, and implementing this strategy could lead to unexpected, hard-to-debug behaviour for developers.
We could “fan-out” writes, meaning that each cache write needs to be committed to each cache before it’s successful. This would make cache writes slower, but reads much faster. Our data (and Pantheon’s) show that writes tend to happen a lot in real-world use cases, and this could hurt the performance of the whole system. We’d also need to use consensus algorithms to ensure writes have been fully committed, and adding or removing horizontally-scaled instances would introduce overhead too.
What if we took this fan-out approach, and handled it asynchronously? Instead of blocking our initial write, we would let each cache know that a key has been updated, and the replica caches can invalidate it internally to force a refresh. The primary constraint is that when a value is invalidated and updated, it should be invalidated on the replicas before it is read – this ensures Consistency (the C in CAP) of read-after-write operations, like loading the post editor after saving some changes to that post.
It’s here where Redis really shines. When we start a replica cache, it connects to our primary Redis instance, and immediately starts listening for changes to data. The replicas store fetched values in memory, and whenever the value is updated in Redis, every replica receives a notification to invalidate the key. This works automatically for each client, allowing them to join and leave at any time.
Performance & scaling: As close as possible
Afterburner Cache moves the cache even closer to the PHP request, by implementing this layered caching within a PHP extension. The PHP extension directly stores PHP objects in memory, shared across multiple requests.
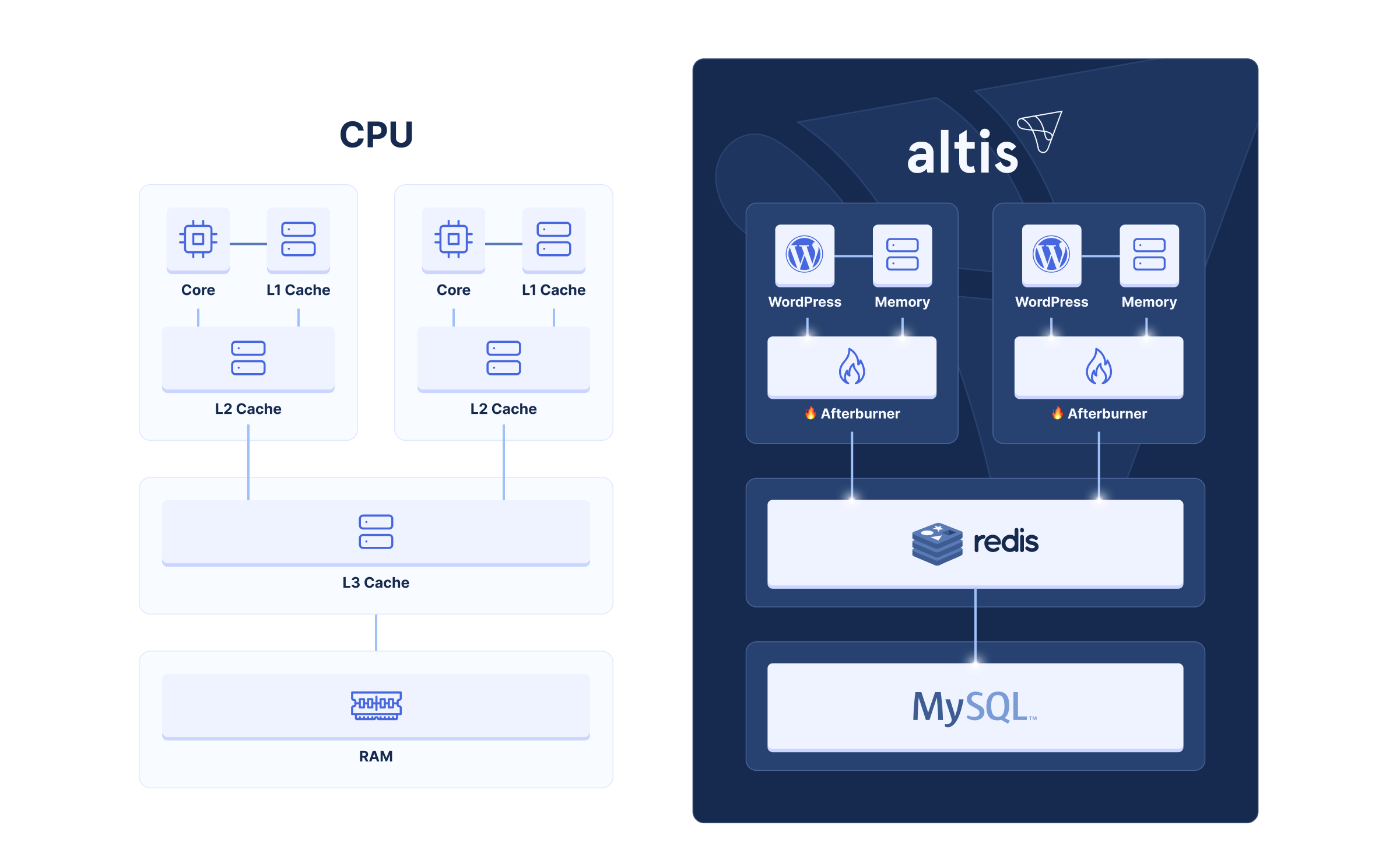
In addition to enabling connection pooling to Redis (removing the connection latency penalty), this also means that our cache can avoid deserialization overheads. In WordPress, this is typically only possible using APCu or other in-memory solutions – meaning that we now have a scalable multi-server cache with the same or better performance compared to a single-server.
Afterburner Cache allows us to break free of the performance-scaling trade-off, driving massive gains in performance – up to 30% faster page loads, even at scale. Even better, it’s a drop-in replacement for existing object caches, giving developers and customers these benefits with no changes to their code.
What’s next?
With Altis, we have a fundamentally different approach to performance and scaling than many other hosts. We take an opinionated take to running WordPress at scale, and this gives us the ability to take problems at any layer – from overriding code in WordPress itself, to optimizing server hardware for specific customer needs.
Afterburner is fundamental to our performance focus, and we’re continuing to develop new features and functionality for it. Alongside Afterburner Cache, Afterburner Translations is already improving performance for multilingual customers.
Our mission to make high scale and high performance easy for you is never-ending. Stay tuned – we think you’ll love what’s coming next.